The problem with trusting a score you can’t verify
Search for ‘IQ test online’ and you will find no shortage of results. Mensa sells access to a supervised version of its own test. Sites like 123test and iqtest.net offer instant scores after a few minutes of puzzles. Listicle aggregators rank them all. What almost none of these pages do is explain what is actually happening under the hood: who built the test, on what population it was normed, what the score means relative to a clinical standard, and why any of that matters.
This article tries to fill that gap. It is not a ranking of which site to use. It is an explanation of the machinery behind online cognitive tests, so you can read any score you receive with appropriate calibration.
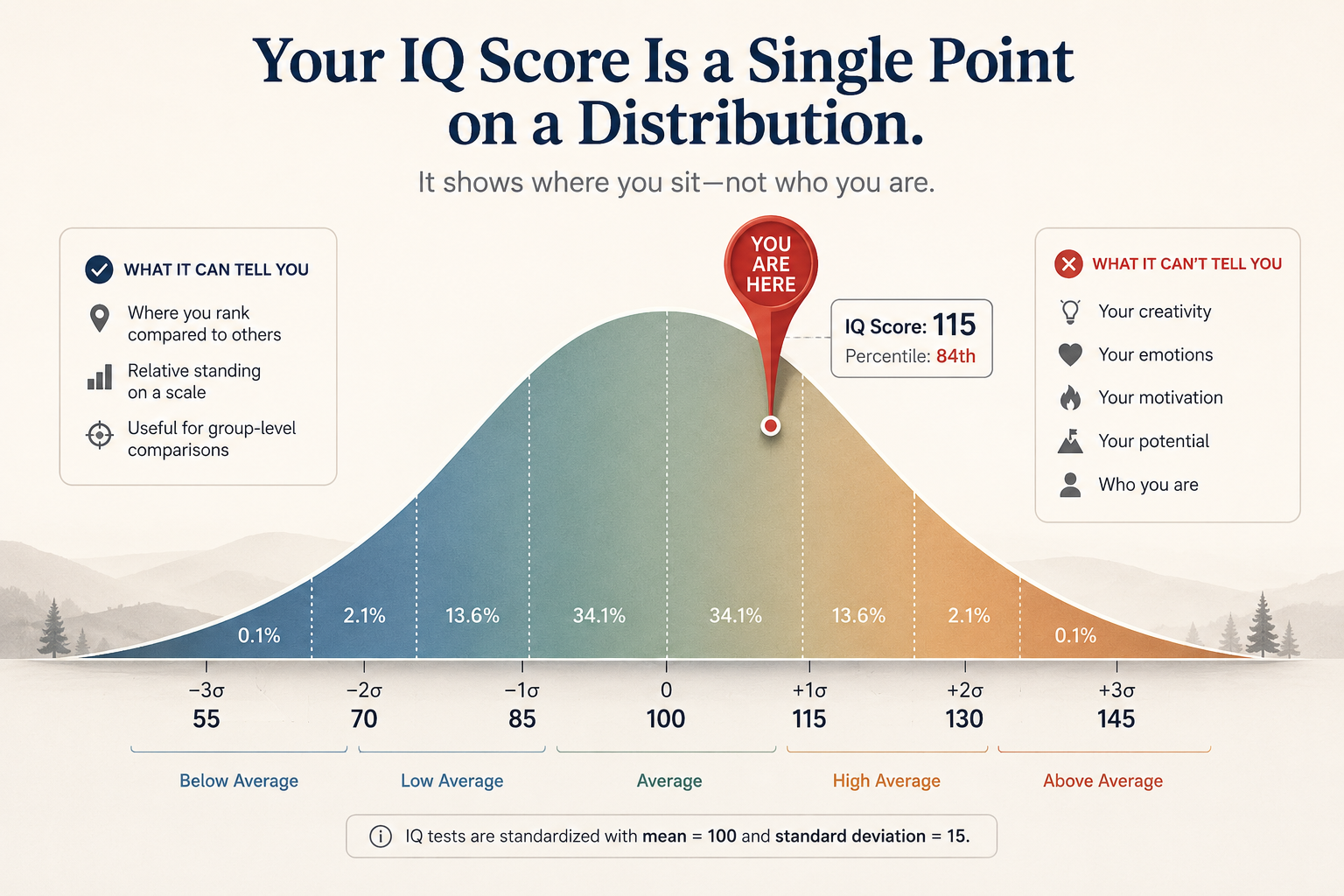
What an IQ score is supposed to represent
The number you receive from any IQ test is a relative score, not an absolute measurement of something fixed in your brain. The modern convention, established by David Wechsler in the 1930s and now universal, is to set the population mean at 100 with a standard deviation of 15. A score of 115 means you performed better than roughly 84% of the reference population. A score of 130 means better than roughly 98%.
The key phrase is ‘reference population.’ A score only means something if the test was normed on a large, representative sample of the population you belong to. The Wechsler Adult Intelligence Scale (WAIS-IV), for example, was normed on 2,200 adults stratified by age, sex, education level, and geographic region to match U.S. Census data. The Stanford-Binet 5 used a similarly structured sample of 4,800 individuals. Those sample sizes and stratification procedures are what make a clinical score interpretable.
When a website tells you your IQ is 127 after a ten-minute test, the implicit claim is that the same norming logic applies. Usually, it does not.
The four categories of online IQ test
Not every online test is the same kind of thing. It helps to sort them into rough categories before evaluating any individual product.
Adapted clinical instruments
A small number of online platforms license or adapt genuine psychometric instruments. Some neuropsychology platforms used by clinicians deliver validated subtests remotely, though always under supervision and with caveats about ecological validity (the concern that test performance at home differs from performance in a controlled room). These are the closest online equivalent to in-person testing, but they are not freely available to the general public and they still carry disclaimers about remote administration.
Research-grade adaptive tests
Some academic groups have released online cognitive batteries for research purposes. The International Cognitive Ability Resource (ICAR), developed by Condon and Revelle (2014), is a publicly available, psychometrically validated set of items covering matrix reasoning, letter-number series, verbal reasoning, and three-dimensional rotation. ICAR items have been validated against clinical instruments in published samples. Tests built on ICAR items are meaningfully more defensible than most commercial alternatives, though they still lack the individual-level norming of a supervised clinical test.
Commercial entertainment tests
The majority of free online IQ tests fall here. They typically consist of 20 to 40 items, often matrix-style or spatial puzzles, scored against an internal reference group that is not disclosed. The norming population is usually whoever has taken the test before, which means it skews toward the kind of person who seeks out IQ tests online: younger, more educated, more likely to be male, and almost certainly not representative of the general population. The result is systematic score inflation. If the reference group scores higher on average than the general population, everyone’s score gets pulled upward.
This is not a conspiracy. It is a predictable consequence of convenience sampling, and it is rarely disclosed.
Outright score generators
At the far end of the spectrum are tests that produce high scores regardless of performance, because high scores drive shares and return visits. These are not psychometric instruments by any reasonable definition. They are engagement tools dressed in the language of measurement. The tell is usually a score distribution that clusters suspiciously high: if the ‘average’ score on a test is 118, something has gone wrong with the norming.
What separates a defensible online test from a flattering one
Four criteria separate a test worth taking from one that is mainly entertainment:
Norming transparency. A defensible test tells you the size and composition of its reference sample. If a site cannot tell you how many people were in the norming group, or whether that group was demographically representative, the score is uninterpretable in any rigorous sense.
Item validation. Individual test items should have known psychometric properties: difficulty parameters, factor loadings, and ideally published reliability coefficients. Items scraped from puzzle books or invented without calibration can produce scores with no consistent relationship to validated measures.
Score distribution disclosure. A well-normed test produces a roughly normal distribution of scores centered near 100. If a site’s score distribution is not published, or if anecdotal reports cluster around 115 to 130, that is evidence of inflated norming.
Honest scope claims. A test that tells you your score is ‘just like the real IQ test’ or implies clinical equivalence without supervision, standardised administration, and a validated norming sample is making a claim it cannot support. Honest tests describe what they measure and what they do not.
The administration problem
Clinical IQ tests are administered under controlled conditions for reasons that go beyond formality. Standardised instructions, time limits enforced by a human examiner, a quiet room, and the absence of reference materials all affect performance. The Wechsler and Stanford-Binet manuals specify exact wording for every instruction because even small variations in phrasing can shift scores.
Online tests cannot control any of this. You might take the test at 11pm after a long workday, with notifications pinging, in a browser with Wikipedia one tab away. Or you might take it on a focused Saturday morning after coffee. These are not equivalent testing conditions, and the score difference between them can be substantial.
This is not an argument that online tests are worthless. It is an argument that the error bar around any online score is wider than the number implies. A clinical score from a trained examiner carries a standard error of measurement of roughly 3 to 5 points (depending on the instrument and subtest). An online score, absent controlled administration, carries a much larger effective uncertainty.
What online tests are actually good for
Given all of the above, it would be wrong to conclude that online cognitive tests have no value. They have real value, just not the value often claimed for them.
First, they are useful for orientation. If you have never thought carefully about your cognitive profile, a well-constructed online test can give you a rough sense of where you sit relative to other people who have taken similar tests. That is not nothing. It is a starting point.
Second, they are useful for identifying patterns. A test that breaks out subscores across verbal reasoning, spatial reasoning, and working memory can help you notice which cognitive domains feel easier and which feel harder. That kind of self-knowledge has practical value even if the absolute scores are imprecise.
Third, they are useful for engagement with the underlying science. Taking a test and then reading about what it measures, how it was constructed, and what the research literature says about cognitive ability is a genuinely educational activity. The score is almost secondary to the thinking it prompts.
What online tests are not good for: diagnosing learning disabilities, qualifying for gifted programs, making clinical decisions, or providing the kind of documented evidence that a school, employer, or court would accept. Those applications require a supervised, validated, clinical instrument administered by a licensed psychologist.
The specific case of Mensa
Mensa is worth addressing directly because it appears prominently in searches and because its brand carries an implicit authority claim. Mensa’s qualifying score (the 98th percentile on an accepted test) is real and the organisation does use validated instruments for its supervised admission tests. However, the online ‘Mensa workout’ available on its website is explicitly described by Mensa itself as a practice exercise, not a qualifying test. It does not produce a score that Mensa accepts for membership. The distinction matters: the brand lends credibility to the workout that the workout’s psychometric properties do not fully support.
This is not a criticism of Mensa as an organisation. It is a note that brand recognition and psychometric rigor are different things, and conflating them is easy when you are trying to interpret a score.
Reading your score honestly
If you have taken an online IQ test and received a score, here is a reasonable way to interpret it.
First, find out whether the test discloses its norming sample. If it does not, treat the number as an ordinal rank within an unknown population, not as a standard IQ score.
Second, apply a mental correction for convenience-sample inflation. If the test is free and widely shared, the reference group almost certainly skews above average. A score of 115 on such a test might correspond to something closer to 105 to 110 on a clinically normed instrument. The exact correction is unknowable without the norming data, but the direction is predictable.
Third, pay more attention to relative performance across subtypes than to the headline number. If you consistently score higher on spatial items than verbal items, that pattern is probably more reliable than the absolute score, because the pattern is less sensitive to norming artifacts.
Fourth, if the score matters for a real-world decision, get a clinical assessment. The cost of a clinical evaluation from a licensed psychologist typically runs between $500 and $2,000 in the United States depending on the depth of the battery, but the result is interpretable in a way that no online score can match.
What we do here
Stanford-Binet Online offers a free, self-administered cognitive assessment built around the reasoning traditions of the original Binet-Simon scale. It is not a clinical Stanford-Binet 5 administration. It does not produce a score that a psychologist, school, or employer would accept as a formal IQ result. What it does produce is a structured, reasonably constructed estimate of your performance on a set of cognitive tasks, with honest explanations of what those tasks measure and what the score means.
The goal is to be one of the more transparent options in a landscape that is not, on average, very transparent. If you want to understand more about how the score is generated and what its limits are, the accuracy and methodology page goes into detail. If you want to understand the five cognitive factors the assessment draws on, the page on what the Stanford-Binet measures explains the structure.
For context on how the original Binet-Simon scale was constructed and why its design choices still echo through modern testing, the origin story of the Stanford-Binet is worth reading before or after you take the test. And if you want a broader map of where online tests sit relative to clinical ones, the guide to where to take an IQ test covers the full range of options with the same kind of honest framing.
If you want to see what the assessment looks like in practice, you can take the free cognitive assessment and read the score explanation alongside the result.
The bottom line
The online IQ test landscape ranges from research-grade instruments with published psychometric properties to score generators that produce flattering numbers regardless of performance. Most tests occupy the middle ground: not fraudulent, but not transparent enough to support the clinical-sounding scores they produce.
The most useful thing you can do before taking any online test is ask three questions: Who normed this, on how many people, and how representative were they? If the site cannot answer those questions, the score it produces is entertainment, not measurement. That does not make it worthless, but it does change what you should do with the number.
FAQFrequently asked questions
Can an online IQ test give me an accurate IQ score?
Online tests can give you a rough estimate of your performance on cognitive tasks, but without a large representative norming sample and controlled administration conditions, the score carries more uncertainty than a clinical result. Treat it as an orientation, not a precise measurement.
Why do most free online IQ tests produce scores above 100?
Because the reference group is usually whoever has voluntarily taken the test, a population that skews toward people who are already interested in cognitive testing and who tend to score above the general population average. This pulls the reported scores upward relative to a properly stratified sample.
What is the difference between an online IQ test and a clinical one?
A clinical IQ test like the WAIS-IV or Stanford-Binet 5 is administered by a licensed psychologist under standardised conditions, normed on a large stratified sample, and produces a score with a known standard error. An online test lacks controlled administration, usually has an undisclosed or unrepresentative norming sample, and cannot be used for clinical or official purposes.
Is the Mensa online test a real IQ test?
Mensa's free online workout is described by Mensa itself as a practice exercise. It does not produce a score that Mensa accepts for membership, and it should not be treated as equivalent to a supervised qualifying test.